
티스토리 뷰
목표
- Hash Table에 대해 설명할 수 있다.
- Hash Table 과정에 대해 설명할 수 있다.
- Hash Table를 Python으로 구현할 수 있다.
요약
Hashing
임의의 길이의 값을 해쉬 함수를 사용하여 고정된 크기의 값으로 변환하는 작업
해쉬 함수
- Division Method : 나눗셈을 이용하는 방법으로 입력값을 테이블의 크기로 나누어 계산한다.(주소 = 입력값 % 테이블의 크기) 테이블의 크기를 소수로 정하고 2의 제곱수와 먼 값을 사용해야 효과가 좋다.
- Digit Folding : 각 Key의 문자열을 ASCII 코드로 바꾸고 값을 향한 데이터를 테이블 내의 주소로 사용한다.
- Mutiplication Method : 숫자로 된 Key 값 K와 0과 1사이의 실수 A, 보통 2의 제곱수인 m을 사용하여 다음과 같은 계산을 해준다. h(k) = (kAmod1) x m
- Univeral Hashing : 다수의 해쉬함수를 만들어 집합 H에 넣어두고, 무작위로 해쉬함수를 선택하여 선택한 해쉬값을 만드는 기법.
Hash Table(해쉬 테이블)
- 해쉬 함수를 사용하여 변환한 값을 색인(Index)로 삼아 키(key)와 데이터(value)를 저장하는 자료구조.
- 데이터를 저장/삭제/조회하는데 평균 시간복잡도는 O(1)이다.
- 데이터 충돌이 발생하는 경우 Chaining에 연결된 리스트들까지 검색한다면 O(N)까지 시간복잡도가 증가한다.
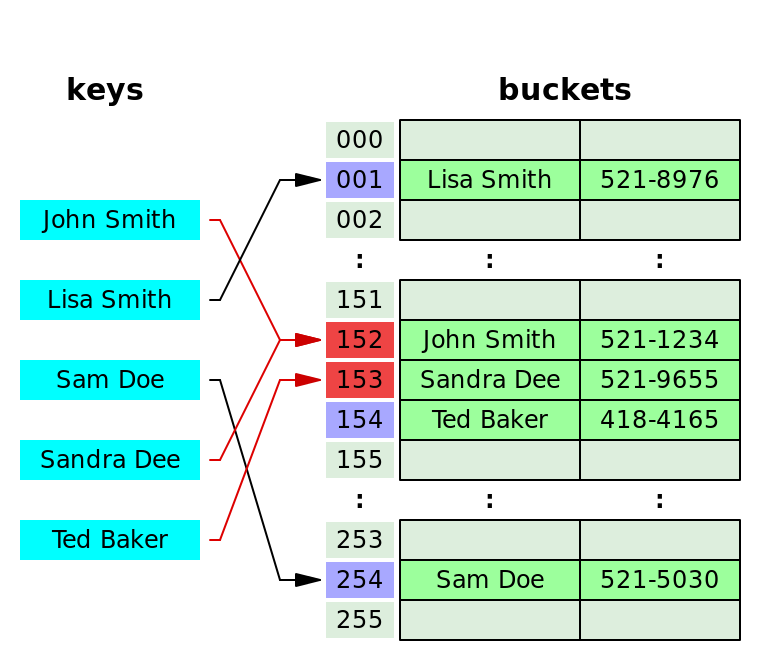
해쉬(Hash)값이 충돌하는 경우
만약 "John Smith"를 해쉬 함수로 돌려 나온 값과 "Sandra Dee"를 해쉬 함수로 돌려 나온 값이 152로 동일하다면 어떻게 해야 할까?
1. 분리 연결법(Separate Chaining)
- 분리 연결법은 동일한 버킷의 데이터에 대해 자료구조를 활용하여 추가 메모리를 사용하여 다음 데이터의 주소를 저장하는 것이다.
- 시간복잡도는 삽입의 경우 연결리스트에 추가하기만 하면 되기 때문에 상수 시간인 O(1)이 걸린다.
- 삭제와 조회의 경우에는 최악의 경우 Key 값의 개수인 K에 대해 O(K)가 걸린다.
- 해쉬 테이블 내에 공간 대비 키 값들이 많이 들어 차있을 수록 충돌할 여지가 늘어나고 해쉬 테이블의 효율도 급격하게 안 좋아진다.

2. Open Addressing
- 원래라면 해쉬함수로 얻은 해쉬값에 따라서 데이터와 키값을 저장하지만 동일한 주소에 다른 데이터가 있을 경우 다른 주소도 이용할 수 있게 하는 기법이다.
- Open Addressing을 구현하기 위한 대표적인 방법은 3가지가 있다.
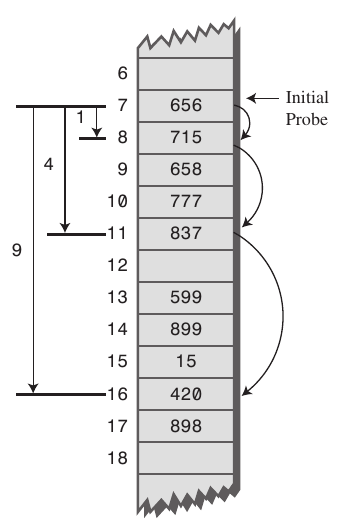
1. Linear Probing
- 현재의 버킷 index로부터 고정폭 만큼씩 이동하여 차례대로 검색해 비어있는 버킷에 데이터를 저장한다.
- "John Smith"의 해쉬값과 "Sandra Dee"의 해쉬값이 152로 동일하지만 "Sandra Dee"가 나중에 들어왔기 때문에 153으로 들어가고 "Ted Baker"의 해쉬값은 153이지만 "Sandra Dee"가 이미 들어가있기 때문에 154로 들어간다.
- 바로 인접한 인덱스에 데이터를 삽입해가기 때문에 데이터가 밀집되는 클러스터링 문제가 발생하여 탐색과 삭제가 느려지게 된다.
2. 제곱탐사 (Qudratic Probing)
- 1^2, 2^2, 3^2 ...으로 탐사를 하는 방식으로 선형탐사에 비해 더 폭넓게 탐사하기 때문에 탐색과 삭제에 효율적일 수 있다.
- 초기 해쉬값이 같을 경우에 탐사하는 역시나 클러스터링 문제가 발생하게 된다.
3. 이중해싱(Double Hashing)
- 해쉬된 값을 한번 더 해싱하여 해쉬의 규칙성을 없애버리는 방식이다.
- 해쉬된 값을 한번 더 해싱하여 새로운 주소를 할당하기 때문에 다른 방법들보다 많은 연산을 하게 된다.
Python 코드
from collections import defaultdict
# import collections
# Definition for singly-linked list.
class ListNode:
def __init__(self, key=None, value=None):
self.key = key
self.value = value
self.next = None
HASHMAP_SIZE = 1000
class MyHashMap:
# 초기화
def __init__(self):
self.size = HASHMAP_SIZE
self.table = defaultdict(ListNode)
# def _hash()
# 삽입
def put(self, key: int, value: int) -> None:
index = key % self.size
# index 값이 비어져 있을 때
if self.table[index].value is None:
self.table[index] = ListNode(key, value)
return
# index 값이 채워져 있을 때
p = self.table[index]
while p: # p == None -->
if p.key == key:
p.value = value
return
if p.next is None:
break
p = p.next
p.next = ListNode(key, value)
# 조회
def get(self, key: int) -> int:
index = key % self.size
# 비어 있다면
if self.table[index].value is None:
return -1
# 링크드 리스트가 있다면
p = self.table[index]
while p:
if p.key == key:
return p.value
p = p.next
return -1
# 삭제
def remove(self, key: int) -> None:
index = key % self.size
# 비어있는 경우
if self.table[index].value is None:
return
# 링크드리스트의 첫번째, head
p = self.table[index]
if p.key == key:
self.table[index] = ListNode() if p.next is None else p.next
return
# 중간에 있는 경우에는, 전, 다음꺼를 연결해주는 경우
prev = p
while p:
if p.key == key:
prev.next = p.next
return
prev, p = p, p.next시간 복잡도
- 각각의 Key 값은 해쉬함수에 의해 고유한 Index를 가지게 되어 바로 접근할 수 있으므로 평균 O(1)의 시간복잡도로 데이터를 조회할 수 있다.
- 데이터 충돌이 발생한 경우 O(N)까지 시간복잡도가 증가할 수 있다.
- 통계적으로 해쉬 테이블의 공간 사용률이 70~80% 정도가 되면 해쉬의 충돌이 빈번하게 발생하여 성능이 저하되기 시작한다.
Reference
반응형
'Programming > 알고리즘' 카테고리의 다른 글
| 이분 탐색 (Binary Search) (0) | 2021.06.10 |
|---|---|
| 계수 정렬 (Counting Sort) (0) | 2021.06.10 |
| 기수 정렬 (Radix Sort) (1) | 2021.06.10 |
| 힙 정렬 (Heap Sort) (0) | 2021.06.07 |
| 합병 정렬 (Merge Sort) (0) | 2021.06.07 |
댓글